Memory in Voice Agents Is a Harder Problem Than You Think
The first time I tried to plug a memory layer into a voice agent, the thing slowed down by hundreds of milliseconds on the first turn and never recovered. The conversation went from natural to “is the line still there?” in a single round-trip, because I had ported a text-agent memory architecture wholesale: a synchronous vector lookup against a hosted store, a small re-ranking pass, then the LLM. On a chat surface, nobody would have noticed. On voice, every turn felt like the agent was buffering before it spoke.
In the voice agents primer I flagged memory as one of the harder engineering problems in the space and promised to come back to it. This is that post. The short version: voice memory is not text memory with a tighter clock. The clock is so much tighter that the entire read/write path has to invert. Most of what you think of as “memory” cannot live in the response critical path at all. It has to be pre-loaded, pre-computed, or written after the fact.
I have spent a fair bit of time staring at memory across surfaces, reverse-engineering how ChatGPT and Claude actually do it, building the layered memory hierarchy inside the Water framework, building BYOM as a portable user-owned memory layer, and then arguing publicly that most AI products shouldn’t ship memory at all. None of those experiences quite prepared me for what voice does to the design space. This post is about the constraints, the tradeoffs they force, the four families of architectures I keep seeing in production, and the things you only learn the hard way.
Why Voice Memory Sits Differently from Text Memory
Text agents come with natural slack. The user types, sees a loading indicator, and tolerates 1-3 seconds before a response. That gap is where most memory work hides in the form of vector lookups, semantic search over past chats, even a quick summarization pass. Text trained users to wait, and you can spend that wait however you like.
Voice does not give you that gift. The expected end-to-end response is 500-800ms, and that budget includes everything: STT finalization, memory lookup, LLM time-to-first-token, TTS first-chunk synthesis, and audio delivery. If memory eats more than 50-100ms of that, the conversational rhythm breaks. A single round-trip to a hosted vector database is often 20-80ms just on the network. Add embedding computation, ANN (approximate nearest neighbor) search, and result formatting, and you have spent your entire memory budget before the LLM has seen a token.
Input format is the second wedge. Text agents receive structured prose, but voice agents receive a streaming transcript of spontaneous speech, including disfluencies, restarts, false antecedents, and corrections. Any fact extraction pipeline that worked beautifully on chat will struggle here.
Turn density is the third. Voice conversations produce shorter, faster, less information-dense turns, typically 10-30 words. A 10-minute call lands at 40-60 turns and 1500-2000 tokens of transcript on average. That sounds manageable until you consider how audio inflates it on speech-native models. OpenAI’s own Realtime API cookbook is blunt: “in practice you’ll often see ≈ 10× more tokens for the same sentence in audio versus text”, and gpt-realtime caps at a 32k window. A modest support call is enough to put you on the wrong side of that line.
The fourth wedge usually gets ignored: the cold-start problem. On a chat surface you almost always have an authenticated session. On telephony voice, you often start with nothing but a phone number and have to identify the caller in the first few hundred milliseconds. Memory architectures that assume “you know who the user is at turn one” are fragile. The good ones make the unknown caller case the base condition.
The Memory Layers That Actually Matter
Three layers are worth caring about, and they line up with how the survey literature talks about agent memory more broadly. The recent “From Storage to Experience” survey frames the same evolution as Storage -> Reflection -> Experience. Letta’s product docs codify roughly the same split as Core -> Recall -> Archival. The labels change, but the layers don’t.
Conversation memory is the current call’s transcript and turn ordering, living in the LLM context window. A long call will overflow a practical 4-8k window before you notice, even though modern models nominally support 128k+ tokens. Stuffing the entire transcript into context slows generation and degrades the model’s effective attention on the parts that matter.
Session facts is the working memory layer. Things established during the current call that have to be carried forward inside it. “The caller’s name is Priya. They are calling about account 4821. They sound frustrated.” This is what the agent must not re-ask for five turns later. Without it, voice agents come across as goldfish, and goldfish behavior is the single fastest way to destroy trust on a phone call.
User profile is the long-term layer. Persistent facts across conversations. Name, preferences, last-call summary, open issues, relationship context. This is what lets a returning caller feel recognized rather than restarting from zero.
The hard design question is the middle two layers: how do you capture and surface session facts within a call, and how do you persist and retrieve user profile information across calls, both under the latency constraints above?
Where the Latency Actually Goes
Let’s make the constraint concrete. A typical voice agent response cycle looks like this:
- User stops speaking -> VAD detects end of turn (~100ms)
- Final transcript arrives from streaming STT (~50ms after VAD)
- Memory retrieval runs (how long?)
- LLM receives augmented prompt -> TTFT (~300ms for a fast model)
- TTS first audio chunk (~100ms after first tokens)
- Total target: ~600ms from end of user speech to first audio
Step 3 is where memory lives, and it has to fit in roughly 50-100ms to stay under that 600ms total.
That immediately rules out most of the obvious approaches. A synchronous vector search at turn time runs 30-100ms for the query, plus another 50-100ms for embedding, ranking, and formatting. Mem0’s own voice agent memory guide puts semantic search at “50-200ms depending on your vector store and infrastructure”. Even Zep, engineered specifically for low-latency context retrieval, advertises P95 of <200ms standalone and <250ms with LiveKit voice agents. Those numbers are great for chat. For voice they live at the very edge of acceptable, and only on the median, never the tail. An LLM-based summarization pass at turn time is a non-starter, 300-800ms blows the entire budget before the main LLM has even started. The one option that genuinely works is a key-value fetch from a fast in-process cache or a local Redis: 1-5ms, predictable, invisible.
The Four Questions Behind Every Voice Memory Architecture
Once you have internalized “memory work cannot live in the critical path”, the design space collapses to four decisions. You can find the same four questions implicit in every production memory system I have looked at, Letta, Zep, Mem0, A-MEM, MemoryBank, Generative Agents, even though each of them answers the questions differently. Pin them down and most of the architecture follows. (Mem0’s voice memory guide is a useful read on the same terrain if you want a vendor’s point of view.)
When do you write? Per-turn (fact-extract after every exchange) or per-session (batch at end-of-call). Per-session is cheaper and produces cleaner extractions because the model sees the whole arc. Per-turn is more expensive and noisier, but durable: if the process crashes mid-call, the WebRTC session dies without a clean disconnect, or the end-of-call extraction itself fails, per-session loses everything for that call while per-turn keeps every fact written through the last successful turn. Almost every production voice deployment I have seen accepts the cost penalty and runs per-turn, because abnormal terminations are routine in telephony and “we lost the transcript” is not a failure mode you want to debug live. (A third option, sleep-time writes, gets its own section below.)
What do you write? The question I would ask of every candidate fact is: would this actually change how the agent responds in a future session? If not, it’s noise, and noisy memory hurts more than absent memory because it makes retrieval less precise on the things that do matter. In practice this means the more specialized your use case, the more aggressive your filtering should be. A general assistant can afford generic LLM driven extraction. A medical intake agent should be writing into a typed schema and rejecting anything that doesn’t fit.
How do you retrieve? Four patterns dominate:
| Pattern | When it works | What it costs |
|---|---|---|
| Dump everything | Users with <20-30 memories | Token bloat past the threshold; “lost in the middle” past long contexts |
| Pure semantic search | When relevance per-turn is the bottleneck | 50-200ms per turn - usually too much for voice |
| Pre-loaded context | When the user has stable, summarizable history | Stale within long sessions; cold-start has nothing to load |
| Hybrid (pre-load + on-demand) | Most production voice agents | Requires a topic-shift detector, but it’s the right default |
Where does the work happen? Inline, parallel (a memory agent alongside the voice pipeline), or post-processing. For voice, the answer is almost always parallel for writes and pre-loaded for reads, with inline retrieval reserved for the tightest cases.
These four answers, taken together, decide which architecture family you are in.
The Architecture Landscape
I would group the voice memory architectures I have looked at into roughly four families. They aren’t mutually exclusive but most real systems blend at least two and they make for a useful map.
Family 1: Native framework state
Every serious voice agent framework maintains conversation state inside the pipeline for the duration of a session, and the major end-to-end speech APIs do the same on their side, often with built-in context truncation. This family handles only the within session problem and nothing survives the call. Treat it as the floor of any architecture, not the architecture itself which is useful as the place to put session facts, useless for anything across calls.
End-to-end speech models collapse the STT-LLM-TTS pipeline into a single stateful session and solve the latency of pipeline problem outright, but they don’t solve the memory problem. OpenAI’s Realtime API caps at a 32k token session, Google’s Gemini Live discards session state at the end of every call, and neither has any built-in concept of cross-session persistence beyond what you wire up around them. Whatever architecture you would have built around a cascade pipeline, you still have to build around an end-to-end one. One genuine upside is that multimodal models can process audio directly, so fact extraction can operate on raw audio rather than a text approximation, which matters for any domain where paralinguistic signal (hesitation, tone, affect) actually shapes the response.
Family 2: Bolted-on memory services
This is where most teams I have talked to start: drop a third-party memory service into the pipeline as a processor between the user aggregator and the LLM, configure a user/entity ID, and let it handle the read/write loop. Mem0, Zep, Hindsight, and Supermemory all ship plugins for the major voice frameworks. The shared shape across all of them is pipeline level integration, user/entity scoping, async writes, and either pre-loaded or on-demand retrieval. The differences are mostly storage substrate (vector vs graph vs SQL), how aggressive the extraction is, and per-call ergonomics.
Family 3: Knowledge-graph memory
This is the family I find most interesting because it actually changes what “memory” means, not just how fast you can fetch it. Instead of embedded text chunks retrieved by similarity, knowledge-graph systems store entities, relationships, and temporal validity, and retrieve by graph traversal augmented with semantic search. The model gets “John’s favorite song is ‘Viva La Vida’ by Coldplay (valid: 2024-01-15 to present)” instead of three loose chunks of past dialog. The production option I have seen show up most often is Zep’s Graphiti; the most interesting academic entry is A-MEM (NeurIPS 2025), which writes each memory as a Zettelkasten-style note that other memories can update over time, so the graph is actively reorganized rather than just appended to. The cost is complexity: graphs are harder to debug, harder to evict from, and more expensive to build than a flat vector index, but for any voice agent that will be on the phone with the same user for years, this family is where the long-term answer lives.
Family 4: Cognitive architectures
The fourth family treats memory as a cognitive process and not as a database. The foundational reference is Park et al.’s Generative Agents (UIST 2023) a memory stream, a reflection step that periodically synthesizes higher-level insights, and a retrieval policy scoring candidates on recency, importance, and relevance. Reflection is the part everyone copies, because it’s what makes the agent feel like it understands you over time rather than parroting what you said. Variants add other tricks: MemoryBank introduces an Ebbinghaus-style forgetting curve so old unused memories quietly drop out; MemR3 (2025) flips retrieval into a router that decides between retrieve, reflect, and answer on each turn. These rarely ship as turnkey products. They are patterns to steal, reflection schedules, importance weighted retrieval, time-decayed scoring, and graft onto a Family 1 + Family 2 base.
Inverting the Read/Write Path
The pattern that actually works in production, regardless of which family you pick from above, is to split memory operations into two categories: things that happen before the response (retrieval) and things that happen after the response (writing). Keep only the absolutely essential retrieval in the critical path, and make even that as fast as possible through pre-loading.
Pre-load at conversation start. When a call begins, before the user says a word, you have a few hundred milliseconds of setup time, WebRTC connection, audio initialization, codec negotiation. Use that window to fetch the user’s profile, their last-call summary, and any open issues into a session-local cache. When the first turn arrives, your “memory retrieval” is a dictionary lookup, not a network call. Every millisecond you spend fetching profile data on turn one is a millisecond the user spends listening to silence.
The cold-start case is where this gets real. If the caller is anonymous, you can’t pre-load anything user-specific. You either authenticate them in the first turn or two (account number, CRM phone-number lookup during setup) or accept thinner context on the first call and design the prompt to be graceful about it. The mistake I see most often is teams treating authenticated as “the system” and anonymous as an edge case. In telephony, anonymous is a hot path.
The other half of the inversion is async writes. After each response, kick off a fire-and-forget background task that extracts new facts from the latest turn and persists them. By the time the call ends, the profile is largely up to date and none of that work has spent any of your inner-loop latency budget. To handle short calls that hang up before extraction finishes, block the call-end handler on a small timeout (2-3 seconds is usually fine) so in-flight tasks drain. The user has already gone, so there is no latency budget to defend. Then run a full summarization pass over the entire transcript and store it as the canonical record like what the call was about, whether it was resolved, key facts, follow-ups. That summary becomes the last_interaction you pre-load on the next call, and it is the single most underrated artifact in a voice memory system. Both ChatGPT and Claude lean on the same idea in their text systems: a curated summary beats a raw transcript at retrieval time, every single time.
Two things bite you once you actually ship this. First, the pre-load can race the previous call’s writebacks. Imagine a caller asks to be called Alex on one call: the per-turn extraction captures “please call me Alex” and persists it. If the next call’s pre-load reads from a snapshot taken a few seconds before that writeback finished draining, the agent greets them by their old name which erodes trust faster than no memory at all. The fix is the obvious one (always serve the freshest writeback even if your snapshot is older), but the failure mode only shows up once you have real users. Second, per-turn extraction means an extra LLM call on every single turn. At a few cents per call multiplied by 40-60 turns, a 10-minute conversation can land at a couple of dollars in extraction alone which is fine for a high-value support call, ruinous for a free consumer assistant at scale. The honest move is to pick a cheaper model for extraction (a distilled 7-8B is usually plenty), run extraction on a longer rolling window, or bias toward post-call extraction for low-margin use cases.
Compressing Conversation History Within a Call
Even within a single call you will hit the practical context limit faster than you expect. A 10-minute call at normal pace lands at 1500-2000 tokens of transcript alone, and on a speech-native session the 10× audio token inflation pushes you well past where any large context advertisement actually holds up.
The mitigation is a rolling window with summary: keep the last N turns in full, replace earlier turns with a compressed summary. When the transcript hits a threshold (say, 20 turns), kick off an async compression pass that replaces the first 10 with 3-4 sentences. Use a fast small model for this, a distilled 1-3B on a colocated GPU, or a fine-tuned summarizer on CPU. 50-150ms per compression is fine async but would be painful in the critical path.
Selective retention is the other lever. Not all turns are equally valuable “okay”, “got it”, “mm-hmm” contribute close to nothing. Even a length and stopword heuristic, much less a tiny classifier, can drop low-signal turns without losing content. Treat the transcript as something to curate, not a log to preserve.
Long-Term Episodic Retrieval
For structured profile data like name, preferences, known issues, a key-value store is the right answer. Fast, predictable, no embedding required. This is the boring part of memory and it should stay boring.
For unstructured episodic memory that is specific past conversations, detailed historical interactions, you eventually need semantic retrieval. The question is when to do it, and the answer is: not during a turn.
The pattern that works is background relevance preparation. You maintain a representation of the current conversation topic. In practice this is usually the last one or two user turns embedded as a single query vector, sometimes augmented with a small classifier-derived topic label. Periodically, every 3-5 turns, or whenever the topic vector shifts beyond a threshold, you fire an async retrieval query against past conversations. If the retrieval finds something relevant, the result gets staged for injection on the next turn, not the current one.
That introduces a one-turn lag on episodic context, and that tradeoff is almost always the right one. Users won’t notice that the agent referenced a past conversation a beat after the topic came up. They will absolutely notice if every turn has a 200ms hesitation.
The honest counterpoint is rapid topic shift. If a user pivots topics every turn which happens more in casual support calls than you would expect your staged retrieval is constantly stale. The pragmatic fix is to detect the shift cheaply (cosine similarity drop between consecutive query vectors) and fall back to a “no episodic context” path rather than injecting yesterday’s topic into today’s question. Stale context is worse than absent context.
Sleep-Time Memory Consolidation
Per-turn writes plus end-of-call summarization handle the basics. The next-level move is doing memory work between sessions, while the system is idle. The clearest articulation of this is Letta’s sleep-time compute, which spawns a separate agent that shares memory blocks with the user-facing agent and runs in the background, reorganizing and consolidating what’s there. The paper that motivated it reports a ~5× test-time compute reduction at equal accuracy and 13-18% accuracy lifts when queries are predictable. Those are the paper’s headline numbers on their chosen benchmarks; for voice, the more useful framing is that even modest consolidation work between calls pays back in retrieval quality on the next one.
The intuition for voice is straightforward. Per-turn writes give you a flat, time-ordered stream of facts. Over weeks and months, that stream accumulates contradictions (“user prefers email”… “user said please call them”) and stale context. A nightly sleep-time consolidation pass can merge duplicates, resolve contradictions in favor of the more recent signal, prune low-importance memories with a forgetting-curve schedule, and synthesize higher-level reflections in the spirit of Park’s Generative Agents — “this user tends to call when something is broken, not for general questions.”
The reason this matters specifically for voice is that you cannot afford to do any of this consolidation work in the critical path. Sleep-time is the only place in the architecture where you have unlimited latency budget. Anything you don’t do here, you’ll regret doing inline.
Clean Signal: Transcripts and Multiple Speakers
All of this assumes the input to your memory pipeline is reasonably clean. In practice it isn’t, and there are two distinct problems hiding in there: noisy transcripts of the caller’s own speech, and the fact that there’s often more than one person in the room.
On the first: voice transcripts are messy. Users say “um” and “uh”, they restart sentences, they use pronouns without antecedents (“tell me about that thing we talked about”). Raw transcripts make for noisy fact extraction. The mitigation is a lightweight transcript cleaning step, a fast pass that removes disfluencies and normalizes references before passing the text into any memory pipeline. This runs asynchronously and never touches the response cycle. The LLM itself sees the raw transcript (because cleaning it adds latency you cannot afford), but memory extraction works off the cleaned version.
The second problem is the one almost no production voice agent solves cleanly. Family customer service calls have a spouse and a kid in the same room. Healthcare calls have a caretaker. Inbound support from a small business has someone shouting context from across the office. Speaker diarization, figuring out who said what is what makes memory accurate here. Without it, your fact extractor cheerfully writes “caller’s spouse hates the current plan” into the caller’s profile, which destroys trust on the next call. pyannote-audio is the dominant open-source option; newer LLM-grounded systems like TagSpeech and DM-ASR show meaningful gains on overlap-heavy audio. Though the latency cost is real with 200-400ms of additional latency per turn on the critical path which is why most production voice agents I have seen don’t ship live diarization aware memory. The workable compromise is to run diarization async on the post-call recording, attribute facts to the right speaker before persisting, and accept some attribution noise within the call itself. It’s the kind of thing that goes wrong rarely enough to be acceptable and wrong badly enough that you should at least have a story for it.
The Three-Tier Stack
Putting it together, a production voice memory system has three tiers, defined by latency profile rather than what they store.
Tier 1 - hot cache (1-5ms): pre-loaded at call start. User profile, last-call summary, open issues. Lives in process memory for the call’s duration. Serves every turn lookup essentially instantly.
Tier 2 - background retrieval (50-150ms, async): episodic search between turns, results staged for injection on the next turn. Never blocks.
Tier 3 - async writes (latency irrelevant): fact extraction, profile updates, end-of-call summarization, sleep-time consolidation. Happens after each turn, after the call ends, and during system idle. Feeds Tier 1 for the next call.
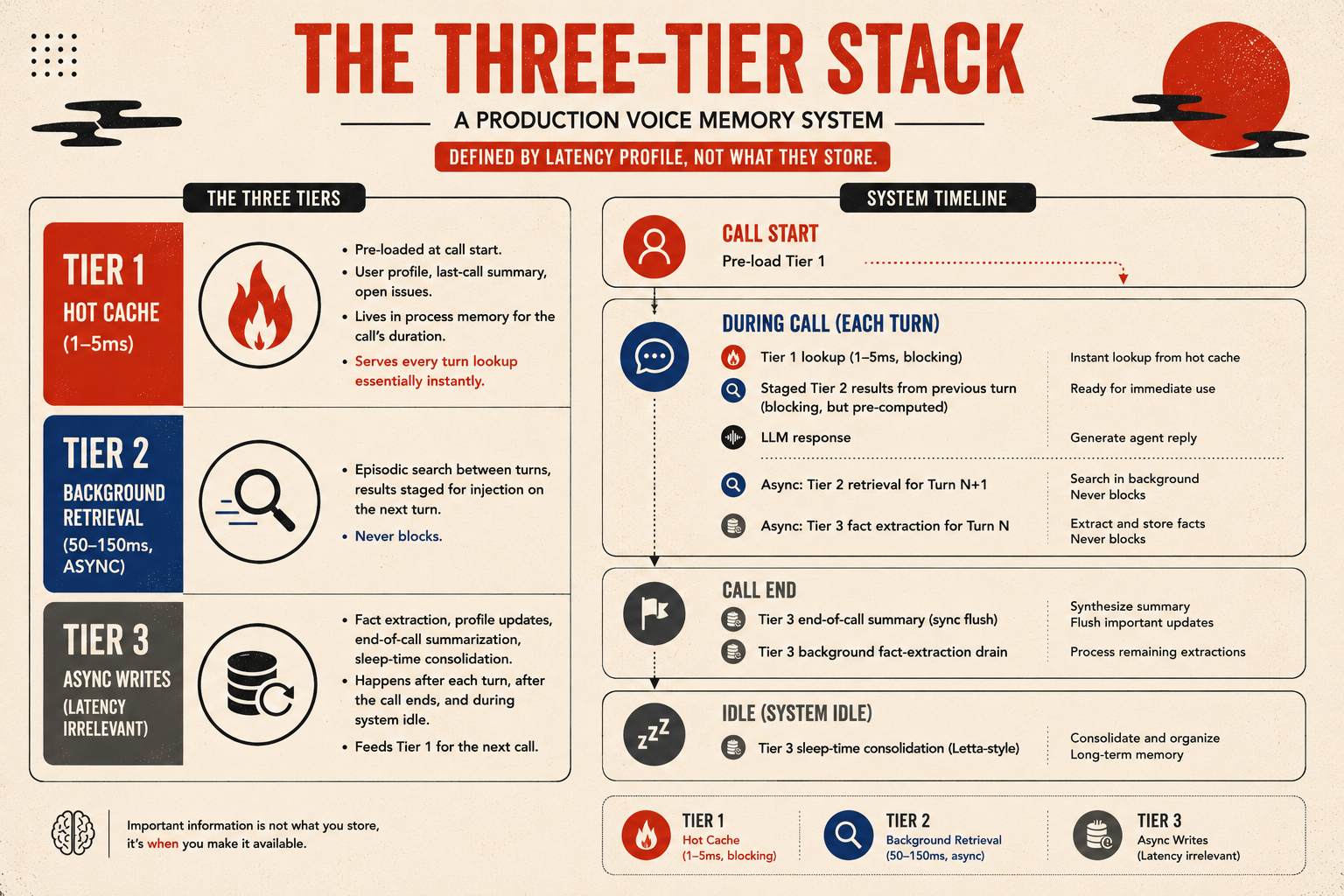
Notice the asymmetry: the only thing on the blocking path is the cache lookup. Everything expensive embedding, retrieval, summarization, writeback, consolidation has been pushed to the cracks between turns, to after the call has ended, or to system idle.
Closing Thoughts
Voice agent memory is still largely unsolved in the sense that genuinely human-like recall across many conversations remains elusive. The infrastructure has fast caches, async extraction, structured profiles, end-of-call summaries, knowledge graphs, sleep-time consolidation and is well-understood and implementable today, with mature frameworks (Pipecat, LiveKit Agents) and a healthy ecosystem of memory services (Mem0, Zep, Letta, Hindsight, Supermemory, Cognee) you can drop in without writing the read/write loop from scratch. The craft lives in the semantic part: deciding what to remember, when to surface it, and how to do it without sounding like the agent is reading from a file. That part rewards careful prompt design and aggressive curation of what gets persisted, not bigger vector databases.
If there’s a single line to take away: in a voice agent, the speed of memory is set by what you have already prepared, not by what you can fetch in the moment.
Next in this series I will cover evaluating voice agents, the part that standard LLM evals (and even LongMemEval and LoCoMo) miss completely, and where most of the hard won lessons from production actually live.
If you found this interesting, I’d love to hear your thoughts. Share it on Twitter, LinkedIn, or reach out at guptaamanthan01[at]gmail[dot]com.
References
- Liu, Nelson F., et al. “Lost in the Middle: How Language Models Use Long Contexts.” arXiv:2307.03172, 2023.
- Park, Joon Sung, et al. “Generative Agents: Interactive Simulacra of Human Behavior.” UIST 2023.
- Zhong, Wanjun, et al. “MemoryBank: Enhancing Large Language Models with Long-Term Memory.” arXiv:2305.10250, 2023.
- Chhikara, Prateek, et al. “Mem0: Building Production-Ready AI Agents with Scalable Long-Term Memory.” arXiv:2504.19413, 2025.
- Xu, Wujiang, et al. “A-MEM: Agentic Memory for LLM Agents.” NeurIPS 2025.
- Du, Xingbo, et al. “MemR3: Memory Retrieval via Reflective Reasoning for LLM Agents.” arXiv:2512.20237, 2025.
- “Sleep-time Compute: Beyond Inference Scaling at Test-time.” arXiv:2504.13171, 2025.
- Luo, Jinghao, et al. “From Storage to Experience: A Survey on the Evolution of LLM Agent Memory Mechanisms.” arXiv:2605.06716, 2026.