Voice Agents 101: The Architecture Behind AI That Talks Back
The first time I built a voice agent and got on a call with it, the thing felt like talking to someone over a satellite phone in 2003. Long pauses, unnatural cadence, occasional cuts where it would just keep talking over me. The text version of the same product was usable. The voice version was not. That was the moment I learned that text engineering and voice engineering are not the same craft.
The moment you introduce audio, you are dealing with a fundamentally different latency profile, a different failure mode surface, and a different set of tradeoffs than anything you would encounter in a text-based system. Voice agents aren’t just LLMs with a speaker attached. They are pipelines, and every stage of that pipeline fights against the same constraint: time.
This post covers how the voice agent pipeline actually works, the architectural choice between cascade and end-to-end speech models, the latency budget you are working within, what full-duplex means and why it is hard, and the design decisions that determine whether your voice agent feels natural or robotic.
The Three-Stage Pipeline
At its core, the most common voice agent architecture is built on three sequential stages.
Speech-to-Text (STT) takes the raw audio from the microphone and converts it into text that the LLM can process. The dominant options here are OpenAI Whisper (open-source, extremely accurate, but has latency), Deepgram (low-latency streaming transcription, production-proven), AssemblyAI (good accuracy, streaming support), and a handful of others. The key metric is not just word error rate but time to transcript — how long it takes to produce a transcript. A 98% accurate transcription that takes 800ms to produce is often worse than a 95% accurate one that takes 150ms.
LLM is the brain. It takes the transcript, applies context and memory, and generates a response. The same models you would use in text apply here, but the prompt structure changes: voice conversations are shorter-turn, more casual, and the model absolutely cannot produce markdown, numbered lists, or long walls of text. Every response needs to be spoken aloud naturally.
Text-to-Speech (TTS) converts the LLM’s text response to audio. The options range from older, robotic systems to modern neural TTS that sounds remarkably human: ElevenLabs, Cartesia (exceptionally low-latency), OpenAI TTS, PlayHT, and others. The metric that matters most in production is time to first audio chunk — how long before the user hears anything at all.
Stitching these three stages together is straightforward but making them feel seamless is not.
Cascade vs. End-to-End Speech Models
Before we get deeper into the cascade pipeline, you should know that there is now a second architectural family that didn’t really exist 18 months ago: end-to-end speech models.
Cascade is what we just described. STT transcribes audio to text, an LLM produces text, TTS turns that text back into audio. You get full control of every stage, complete observability, and the ability to swap components independently. The price you pay is latency (each stage adds time and you can’t always overlap them perfectly), context loss (the LLM never hears tone of voice or hesitation, only the transcribed words), and a flatter emotional surface (the LLM doesn’t know the user is frustrated, and the TTS doesn’t naturally react to the content).
End-to-end speech models bypass the transcription step entirely. The model takes audio in and produces audio out. OpenAI’s Realtime API (built on GPT-4o), Kyutai’s Moshi, and Sesame’s CSM are the prominent examples. Because there’s no STT step and no separate TTS step, latency drops dramatically. Moshi reports response latency in the 200-300ms range which is closer to human conversation than any cascade system can reach. Prosody and emotion are also better because the model directly hears and produces audio without flattening it through text.
The tradeoff is that you give up most of the things that make cascade systems engineerable. You can’t easily inspect what the model “heard.” You can’t swap a better STT in next quarter. Tool calling and structured output are weaker because they have to be encoded into the audio modality rather than handled as text. And the cost per minute of conversation is currently much higher than running a small fast LLM in a cascade.
For most production voice agents in 2026 customer service, telephony, voice front-ends to existing systems cascade is still the right architecture. The control surface, observability, and maturity of the component ecosystem outweigh the latency advantage of end-to-end models. But for use cases where natural conversation matters more than precise tool use (companions, language tutors, hands-free assistants), end-to-end is becoming genuinely competitive. It’s worth knowing both architectures exist before you commit to one.
The rest of this post focuses on cascade because that’s where the engineering surface is most interesting.
The Latency Budget
For a voice conversation to feel natural, the total round-trip from the user finishing a sentence to hearing the first word of a response needs to be under roughly 500-800ms. Beyond that, users start perceiving a delay. Beyond 1.5 seconds, it feels broken. So, you are usually fighting against the clock to get your voice agent to feel natural.
Let’s break down where the time goes in a naive sequential implementation of a voice agent:
| Stage | Typical latency |
|---|---|
| Audio capture + VAD end-detection | 100–300ms |
| STT transcription | 150–400ms |
| LLM Time to First Token (TTFT) | 300–800ms |
| TTS first audio chunk | 100–300ms |
| Network overhead | 50–150ms |
| Total | 700ms–1.95s |
Even at the optimistic end, you are already at the edge of acceptable. At the pessimistic end, it feels like talking to someone with a bad phone connection. This is why voice agents are fundamentally a latency engineering problem, not just an AI problem. The best voice experiences are built by teams that treat milliseconds as a first-class engineering concern.
The solution isn’t to make each stage faster in isolation (though that helps). The real unblock is streaming so that the stages can overlap rather than run sequentially.
Streaming: The Only Way to Win on Latency
In a naive pipeline, you wait for the user to finish speaking, wait for the full transcript, send it to the LLM, wait for the full response, then send it all to TTS. That’s fully sequential and the latency compounds.
In a streaming pipeline, you start TTS as soon as the LLM starts generating tokens and you don’t wait for the full response. The LLM streams token by token, and the TTS system consumes those tokens and begins synthesizing audio in real time, typically buffering 5-15 tokens before generating the first chunk of audio to avoid stopping and starting.
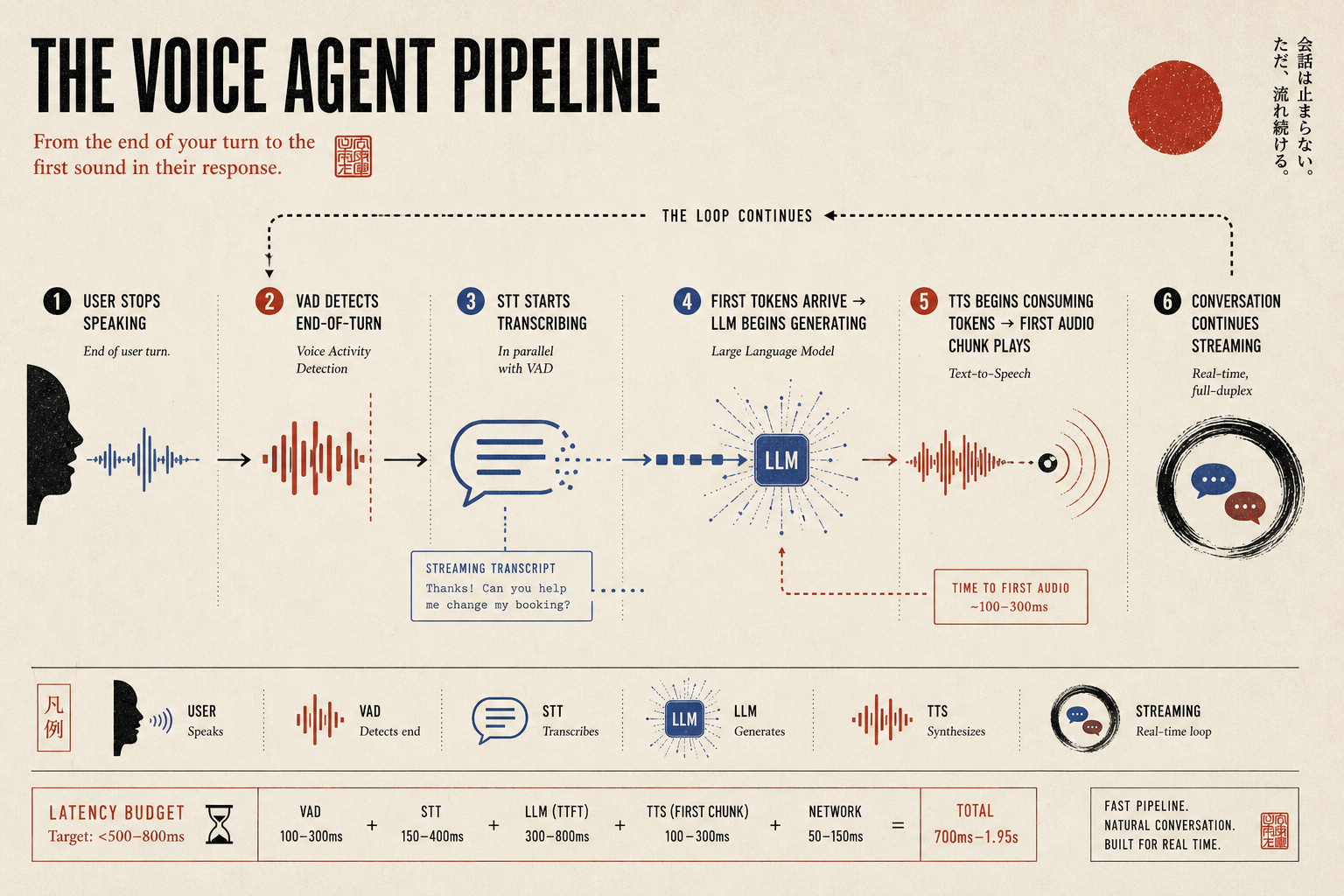
The result is that the user hears the first word of the response while the LLM is still generating the second sentence. This is how production voice systems at companies like ElevenLabs’ Conversational AI, Bland.ai, and Retell AI achieve sub-600ms end-to-end response latency despite using powerful LLMs under the hood.
Half-Duplex vs Full-Duplex
This is one of the most important architectural decisions in voice agent design, and it’s underappreciated.
Half-duplex is the push-to-talk model: one party speaks, then the other speaks. The system listens while the user talks, then responds, then listens again. Simple to implement. Feels like leaving voicemails back and forth. For simple command-response interfaces (think: “set a timer for 5 minutes”), half-duplex is fine. For natural conversation, it’s frustrating.
Full-duplex is how human conversations actually work: both parties can speak simultaneously, interrupt each other, say “uh-huh” mid-sentence, and react in real time. Building this is substantially harder. It requires the system to be listening and generating audio at the same time which means you need to solve the barge-in problem.
Barge-in is what happens when the user starts speaking while the agent is still talking. In a well-designed full-duplex system, the agent detects that the user has started speaking (via VAD), immediately stops its own audio output, cancels any pending TTS chunks, and begins processing the new input. In a poorly designed system, the agent just keeps talking while the user is trying to interrupt, which is deeply annoying.
The technical challenge of barge-in is threefold. First, you need a Voice Activity Detection (VAD) model that can distinguish the user’s voice from the agent’s own audio playback through the speaker, otherwise the agent hears itself and thinks it’s being interrupted. Second, you need to handle the latency gracefully: the moment VAD fires, you need to cut audio within milliseconds, not 300ms later. Third, you need to decide what to do with the partial audio captured during the barge-in. The question is: is it a real input or accidental noise?
The current state of the art uses Silero VAD, a lightweight neural VAD model that runs locally with very low latency (~10ms per 32ms audio chunk). Combined with echo cancellation (filtering out the agent’s own audio from the mic), it gives you a reasonable barge-in detection system.
Turn-Taking Management
Humans don’t just talk and listen in strict alternation. We use backchannels (“mm-hmm”, “yeah”), we start talking slightly before the other person has fully finished, and we use prosodic cues (pitch, rhythm, trailing off) to signal turn-yielding. Current voice agent systems handle this clumsily.
The naive approach is energy-based end-of-speech detection: wait for N milliseconds of silence before deciding the user has finished speaking. The problem is that 500ms of silence is natural in thoughtful speech it doesn’t mean the user is done. Wait too long and the agent feels unresponsive. Wait too short and it cuts off the user.
Better approaches combine silence detection with prosodic analysis (does the pitch fall in a pattern consistent with sentence completion?) and semantic analysis (does the transcript so far form a complete thought?). Some systems use a small, fast LLM to predict whether the user’s utterance is likely complete given the transcript so far, which works surprisingly well.
This is an active research area and the LiveKit Agents framework supports pluggable turn detection strategies including model-based approaches.
The Full Architecture
A production voice agent pipeline typically looks like this:
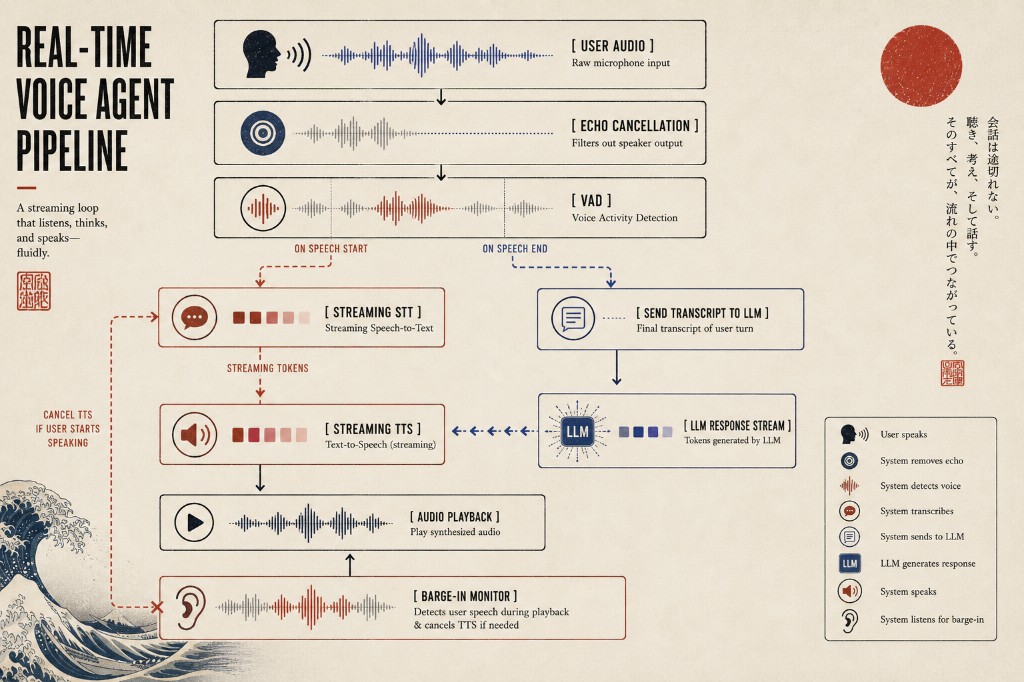
The conversation state (history, memory, context) lives in the LLM prompt, which gets reconstructed for each turn. The audio transport layer (how audio bytes travel between the user’s device and your server) is typically handled by WebRTC for browser-based agents or SIP/RTP for telephony-based ones.
A Minimum Viable Voice Agent
To make this concrete, here is roughly what wiring up a voice agent looks like in practice. This is a simplified Pipecat-style pipeline showing how the pieces snap together — production code adds error handling, observability, and a lot more configuration, but the architecture is the same.
from pipecat.frames.frames import LLMMessagesFrame
from pipecat.pipeline.pipeline import Pipeline
from pipecat.pipeline.runner import PipelineRunner
from pipecat.pipeline.task import PipelineTask
from pipecat.services.deepgram import DeepgramSTTService
from pipecat.services.openai import OpenAILLMService
from pipecat.services.cartesia import CartesiaTTSService
from pipecat.transports.services.daily import DailyTransport
from pipecat.vad.silero import SileroVADAnalyzer
async def main():
# WebRTC transport with built-in VAD and echo cancellation
transport = DailyTransport(
room_url, token, "Voice Bot",
DailyParams(
audio_in_enabled=True,
audio_out_enabled=True,
vad_enabled=True,
vad_analyzer=SileroVADAnalyzer(),
transcription_enabled=False,
),
)
# Three pipeline stages
stt = DeepgramSTTService(api_key=DEEPGRAM_KEY)
llm = OpenAILLMService(api_key=OPENAI_KEY, model="gpt-4o-mini")
tts = CartesiaTTSService(api_key=CARTESIA_KEY, voice_id=VOICE_ID)
# Voice-specific system prompt (more on this below)
messages = [{
"role": "system",
"content": "You are a voice assistant. Keep replies short and natural."
}]
# Wire the pipeline: audio in → STT → LLM → TTS → audio out
pipeline = Pipeline([
transport.input(),
stt,
LLMMessagesFrame(messages),
llm,
tts,
transport.output(),
])
task = PipelineTask(pipeline)
await PipelineRunner().run(task)
That’s it. Forty lines and you have a streaming voice agent that handles VAD, echo cancellation, barge-in, and full-duplex audio over WebRTC. The complexity hidden inside DailyTransport, SileroVADAnalyzer, and the streaming services is enormous, but the application code stays small. Frameworks like Pipecat and LiveKit Agents have done the heavy lifting on the orchestration so you can focus on the parts that are actually unique to your product.
Choosing Your Components
The right component choices depend heavily on your use case:
For lowest latency: Deepgram Nova-2 (STT), a distilled 7-8B model (LLM), Cartesia Sonic or ElevenLabs Flash (TTS). This stack can hit sub-500ms consistently.
For highest accuracy: Whisper large-v3 or AssemblyAI (STT), GPT-4o or Claude Sonnet (LLM), ElevenLabs Turbo (TTS). Accuracy is better but latency is 800ms+.
For telephony deployment: Twilio handles audio transport, Deepgram for STT, small LLM, ElevenLabs or AWS Polly for TTS. The PSTN (phone network) introduces its own latency — typically 150-200ms of jitter buffer alone — so your target response time needs to account for it.
For fully self-hosted, privacy-first: Whisper.cpp (local STT), Llama-3 via Ollama (local LLM), Coqui/VITS or Piper (local TTS). Excellent for private deployments; latency depends on your hardware.
What the LLM Prompt Looks Like
Voice-specific prompt engineering deserves a mention. Responses need to be designed for speech, not text. That means:
- No markdown formatting, bullet points, or headers. These appear verbatim in TTS and sound bizarre
- Short sentences and natural cadence. Long complex sentences with many sub-clauses are hard to follow when spoken
- Avoid lists and use “first… then… finally…” constructions instead
- Contractions and casual register feel more natural in speech
- Build in filler words sparingly (“let me check that for you”) when computation will take a moment
SYSTEM_PROMPT = """You are a voice assistant. Your responses will be spoken aloud.
Follow these rules strictly:
- Respond in natural conversational language, as you would speak it
- Never use bullet points, numbered lists, headers, or markdown
- Keep responses concise — 2-4 sentences for most answers
- Use natural speech patterns with contractions (you are, it is, I will)
- If you need more time to think, say 'let me think about that for a moment'
"""
The Hard Problems That Remain
The basic pipeline I have described is well-understood at this point. The hard problems are what separate mediocre voice agents from good ones.
Noisy environments are the underrated killer of voice agents. A user calling from a coffee shop, or with background TV noise, or with kids in the same room sees STT accuracy drop substantially. The model still produces a transcript, but it’s wrong, and the LLM responds confidently to a query the user never asked. Tools like Krisp and RNNoise help significantly with stationary noise (HVAC, fans, traffic), but non-stationary noise (other voices, music with vocals, sudden loud sounds) is much harder. You can paper over this with voice-specific prompting that asks the user to repeat themselves when confidence is low, but it’s a workaround, not a solution.
Multi-speaker scenarios are the situation almost no production voice agent handles correctly. Imagine a family customer service call: spouse and kid in the same room, both occasionally chiming in. The agent’s STT will produce a Frankenstein transcript blending all three voices, and the LLM will respond to a query that nobody actually asked. Speaker diarization (figuring out who said what) is the answer. Pyannote-audio is the dominant open-source option, but adding it costs 200-400ms of latency on every turn and the accuracy on short utterances is still poor. Most teams just don’t solve this.
Long conversations hit context-window limits faster than text agents because every utterance needs to be transcribed, stored, and fed back as context for every subsequent turn. A 30-minute support call is easily 6,000-10,000 tokens of conversation history alone, before any system prompt or RAG context. You need a memory architecture that summarizes older turns, extracts persistent facts, and reloads relevant context on demand and crucially, all of that has to fit inside the same 500ms latency budget. This is one of the harder engineering problems in the space.
Accents and speaking styles vary STT accuracy dramatically. A model that scores 5% WER on a benchmark of American English speakers might score 15% on Indian English, 20% on Nigerian English, and 30% on heavily accented non-native speakers. Deepgram and AssemblyAI have improved substantially here, but if your product is global, you need to test specifically on the accents your users actually have, not the benchmarks the vendors quote.
The Road Ahead
This primer covers the architecture. The interesting engineering is in the details. In future posts I’ll go deep on the latency stack and where every millisecond actually goes, the barge-in problem and how production systems solve full-duplex correctly, building memory layers that survive within the latency budget, evaluating voice agents (which standard LLM evals completely miss), telephony infrastructure including WebRTC versus SIP and the codec choices that matter, and how modern TTS expresses emotion and prosody.
The voice agent space is moving fast and frameworks like LiveKit, Daily, and Pipecat have made the infrastructure significantly more accessible than it was even 18 months ago. The architectural patterns are converging. The challenge now is in the details: making the latency actually feel like presence, making the memory actually feel like continuity, and making the turn-taking actually feel like a conversation.
If you’re building anything in this space, I’d love to hear about it.
If you found this interesting, I’d love to hear your thoughts. Share it on Twitter, LinkedIn, or reach out at guptaamanthan01[at]gmail[dot]com.
References
- Silero VAD — Lightweight neural voice activity detection
- LiveKit Agents — Open-source voice agent framework
- Pipecat — Open-source framework for voice and multimodal AI applications
- Deepgram Nova-2 — Low-latency streaming STT
- Cartesia Sonic — Ultra-low-latency neural TTS
- Kyutai Moshi — Open end-to-end speech model with sub-300ms latency
- OpenAI Realtime API — End-to-end speech via GPT-4o
- Latency benchmarks from ElevenLabs, Bland.ai, and Retell.ai public documentation