The Art of Prompt Engineering
LLMs are prediction engines. The model takes text as input and then predicts the probability distribution of the next token based on the data it has been trained on. The LLM repeats this process multiple times, adding the previously predicted token to the input and predicting the next token. When we prompt the model, we are steering the model to predict the right sequence of tokens. Prompt engineering is the art of crafting the right prompt to get the model to predict the accurate output.
Many aspects of the prompt affect the efficacy of the model’s output. The LLM in use, the model’s training data, model configuration, choice of words, style and tone, structure, and context are all important factors. In this blog post, we will explore the different aspects of prompt engineering and how they can be used to get the best output from the model.
Sampling Controls
Temperature, Top-P, and Top-K are the most common configuration settings that determine how predicted token probabilities are processed to choose a single output token.
Temperature
It controls the randomness in the selection of the next token. A higher temperature means more randomness in the selection of the next token. A lower temperature means a more deterministic selection of the next token. A temperature of 0 means the model will always choose the most likely next token.
Top-K
Sampling selects the top-k tokens with the highest probability for the next token. The higher the k, the more creative the model gets; the lower the k, the more factual the model gets
Top-P
Sampling select the top tokens whose cumulative probability doesn’t exceed value P. P lies in the range of 0 (most deterministic) to 1 (most random).
Note:
- If you set the temperature to 0, top-p and top-k are irrelevant. The most likely token is the only token selected. If you set the temperature extremely high, the temperature becomes irrelevant. Tokens are selected through top-k and top-p criteria and then randomly sampled.
- If you set top-k to 1, temperature and top-p are irrelevant. The token with the highest probability is the only token selected. If top-k is set extremely high (size of vocabulary), any token with a non-zero probability can be the next token, reducing the output quality and coherence.
- If you set top-p to 0, temperature and top-k are irrelevant. The token with the highest probability is the only token selected. If top-p is set extremely high (1), any token with non-zero probability can be the next token, reducing the output quality and coherence.
Prompting Techniques
Zero-Shot Prompting
The name zero-shot denotes the fact that the model is not given any examples of the task it is supposed to perform. The model is expected to use its knowledge and understanding to perform the task. It is the simplest form of prompting.
Prompt:
Classify the following message as either 'spam' or 'not spam':
Congratulations! You've just won a brand new iPhone. Click the link below to claim your prize now!
Response:
spam
One-Shot & Few-Shot Prompting
With One-shot prompting, we provide one example of the task the model is supposed to perform. The idea is that the model can learn from the example and use it to perform the task.
Prompt:
Classify the following message as either "spam" or "not spam".
Example:
Message: "Get 50% off your next purchase! Limited time offer."
Classification: spam
Now classify:
Message: "Your package has been shipped and will arrive tomorrow."
Response:
not spam
With Few-shot prompting, we provide the model with a few examples of the task the model is supposed to perform. This approach shows the model a pattern that it needs to follow. As a general rule of thumb, you should use at least 3 to 5 examples to show the model the pattern.
Prompt:
Classify each message as either "spam" or "not spam".
Example 1:
Message: "Get 50% off your next purchase! Limited time offer."
Classification: spam
Example 2:
Message: "Your package has been shipped and will arrive tomorrow."
Classification: not spam
Example 3:
Message: "Congratulations! You’ve won a free cruise. Click here to claim your prize."
Classification: spam
Now classify:
Message: "Meeting has been rescheduled to 3 PM tomorrow."
Response:
not spam
System, Contextual, and Role Prompting
System, contextual, and role prompting are all techniques used to guide how LLMs generate text, but each of them focuses on different aspects of the prompt.
System Prompting
It defines the model’s fundamental capabilities and the purpose of the model. System prompts can also be used to generate a code snippet or to return a certain structure.
There are benefits of returning JSON objects from a prompt response, as it forces the model to create a structure and limit hallucinations.
System prompts can also help control safety and toxicity in the model response. Something small, like “You should be respectful in your answer,” can go a long way in generating more respectful responses.
Prompt:
You are an AI assistant that solves problems using structured reasoning.
You must always:
- Show your reasoning steps clearly before giving a final answer.
- Avoid assumptions when information is missing — instead, ask clarifying questions.
- Be concise, factual, and avoid unnecessary explanations.
Role Prompting
Role prompting involves assigning a role to the model. Defining a role for the model helps in giving it a blueprint of the tone, style, and focused expertise you are looking for to improve the quality, relevance, and effectiveness of the output.
Prompt:
You are currently acting as a travel itinerary planner.
Your task is to create efficient and realistic travel schedules that balance sightseeing, rest, and logistics.
Contextual Prompting
Contextual prompting involves providing the model with additional information that is relevant to the task at hand. It helps the model to understand the context of the task and generate a more relevant output.
Prompt:
Plan a 3-day trip to Rome for a couple interested in history, art, and food.
Context:
- Arrival: Friday morning, 10:00 AM.
- Departure: Monday evening, 7:00 PM.
- Hotel: Near the Colosseum.
- Budget: Moderate.
- Preference: Avoid long taxi rides; prefer walking or public transport.
Instruction:
Create a day-by-day itinerary, with timings, key attractions, meal suggestions, and estimated costs.
Chain of Thought (CoT)
Chain of thought prompting is a technique that encourages the model to think step by step. It is a way to get the model to reason about the task at hand by generating intermediate reasoning steps. By combining it with few-shot prompting, the model can generate better results on complex tasks that require reasoning before arriving at the final answer.
CoT appears to improve robustness when moving between different models. The LLM response includes the reasoning steps, which means more output tokens are generated, which means prediction costs are higher and take a longer time to respond.
Prompt:
You are a reasoning-focused assistant. For the task at hand, you must:
1. Break down the problem step-by-step.
2. Think out loud and show all intermediate reasoning.
3. Avoid skipping steps, and make sure the solution is fully explained.
4. Always follow your reasoning before giving a final answer.
User Request: <Insert user's request here>
Please show your reasoning step-by-step and provide a final answer at the end.
Self-Consistency
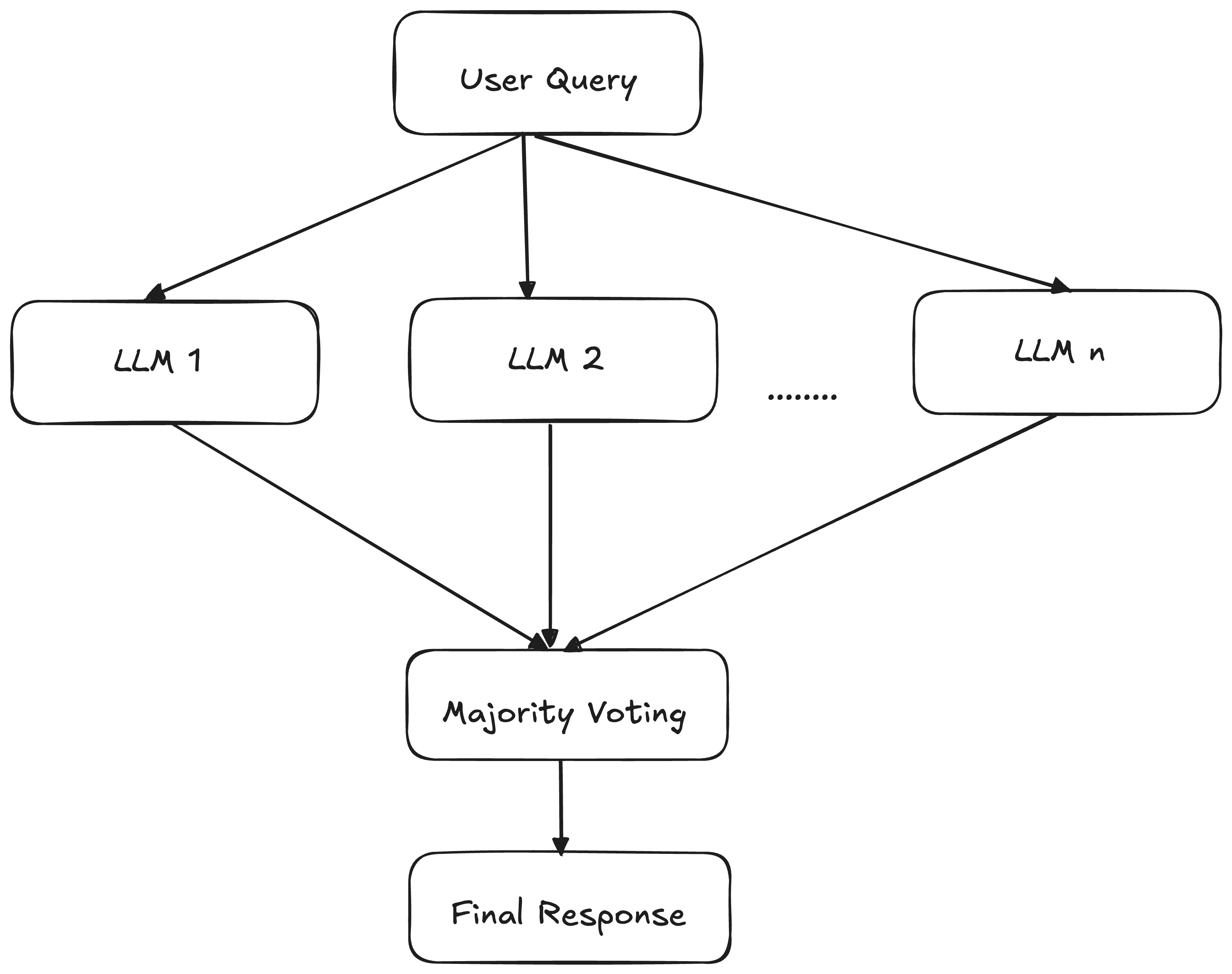
Self-consistency combines sampling and majority voting to generate diverse reasoning paths and select the most consistent answer. It improves the accuracy of the model’s output by considering multiple paths and selecting the most consistent answer.
The steps look like this:
Prompt:
You are a reasoning-focused assistant.
Task: Solve the problem step-by-step, thinking through each part logically before giving your final answer.
User Request: A train travels from City A to City B at 60 km/h and returns at 40 km/h. What is its average speed for the whole trip?
Show your reasoning step-by-step and then give your final answer as:
Final Answer: <number> km/h
- This prompt is sent to the same LLM multiple times (e.g., 5 times) with high temperature (e.g., 0.7-1.0) or multiple LLMs with the same prompt.
Response 1: Reasoning path → Final Answer: 48 km/h
Response 2: Reasoning path → Final Answer: 48 km/h
Response 3: Reasoning path → Final Answer: 48 km/h
Response 4: Reasoning path → Final Answer: 50 km/h
Response 5: Reasoning path → Final Answer: 48 km/h
- Majority voting is done on the final answers.
Final Answer: 48 km/h (48 km/h appears 4 times, 50 km/h appears 1 time)
- The final answer is returned.
Response:
Most consistent answer across reasoning samples: 48 km/h
Explanation: Out of 5 independently reasoned solutions, 4 concluded the speed was 48 km/h.
Tree of Thoughts (ToT)
The Tree of Thoughts technique takes the CoT technique to the next level by exploring multiple reasoning paths simultaneously, rather than following a single linear path.
ToT is well-suited for complex tasks as it works by maintaining multiple reasoning paths in parallel. The model can then explore different reasoning paths by branching out from different nodes in the tree.
Prompt:
You are an expert problem solver.
Use the Tree of Thoughts reasoning process to solve the task:
1. Restate the problem in your own words.
2. Generate 3–4 distinct high-level solution paths (branches).
3. For each branch:
- Break it into detailed steps.
- Provide reasoning for why this path might succeed.
- List potential risks, limitations, or failure points.
4. Compare all branches based on feasibility, efficiency, and reliability.
5. Choose the single best branch and explain why.
6. Output ONLY valid JSON in the schema below.
User Request:
<Insert user's request here>
JSON schema:
{
"thought_branches": [
{
"name": "string",
"steps": ["string", "string", "..."],
"reasoning": "string",
"risks": ["string", "string", "..."]
}
],
"comparison": "string",
"selected_plan": {
"name": "string",
"steps": ["string", "string", "..."],
"reasoning": "string"
}
}
ReAct (Reason & Act)
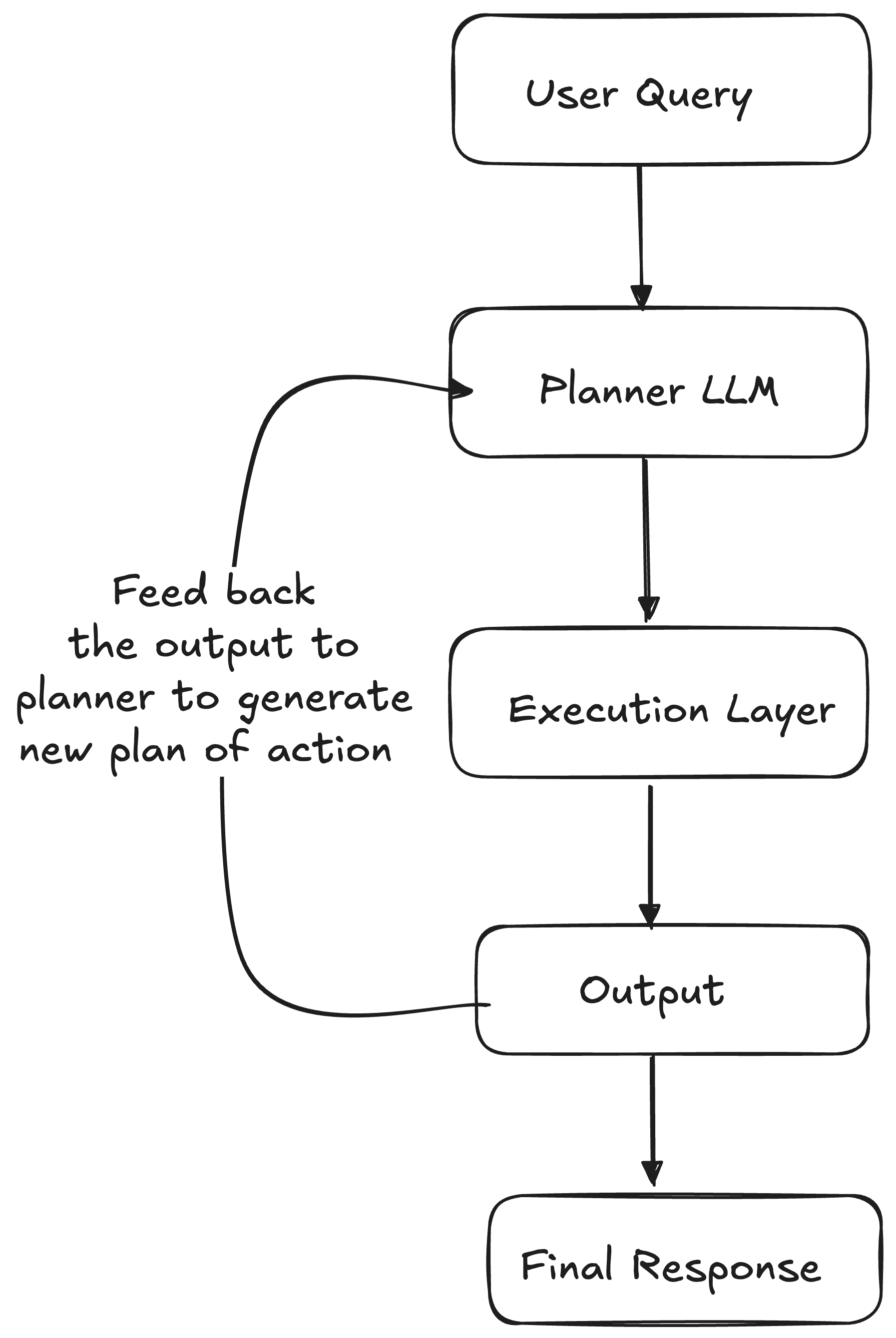
ReAct prompting works by combining reasoning and acting into a thought-action loop. The LLM first reasons about the problem statement and generates a plan of action. It then performs the actions in the plan and observes the result. The LLM then uses the observations to update its reasoning and generate a new plan of action. This process is repeated until the task is completed.
Parting Words
There are many more technique to prompt engineering. This blog post only scratches the surface of the topic. If you are interested in learning more, you can check out this survey paper on prompt engineering.
If you liked the blog, don’t forget to share it and follow me on Twitter, LinkedIn, and Peerlist, and tag me. You may also write to me at guptaamanthan01 at gmail dot com to share your thoughts about the blog.