Replication in Distributed Systems - Part 2

In the first part of the series, we laid the foundation of replication in distributed systems. We will take this forward in the 2nd part, where we introduce the different consistency guarantees, multi-leader configuration and its comparison with single-leader configuration, conflict resolution, and more.
Reading your own writes
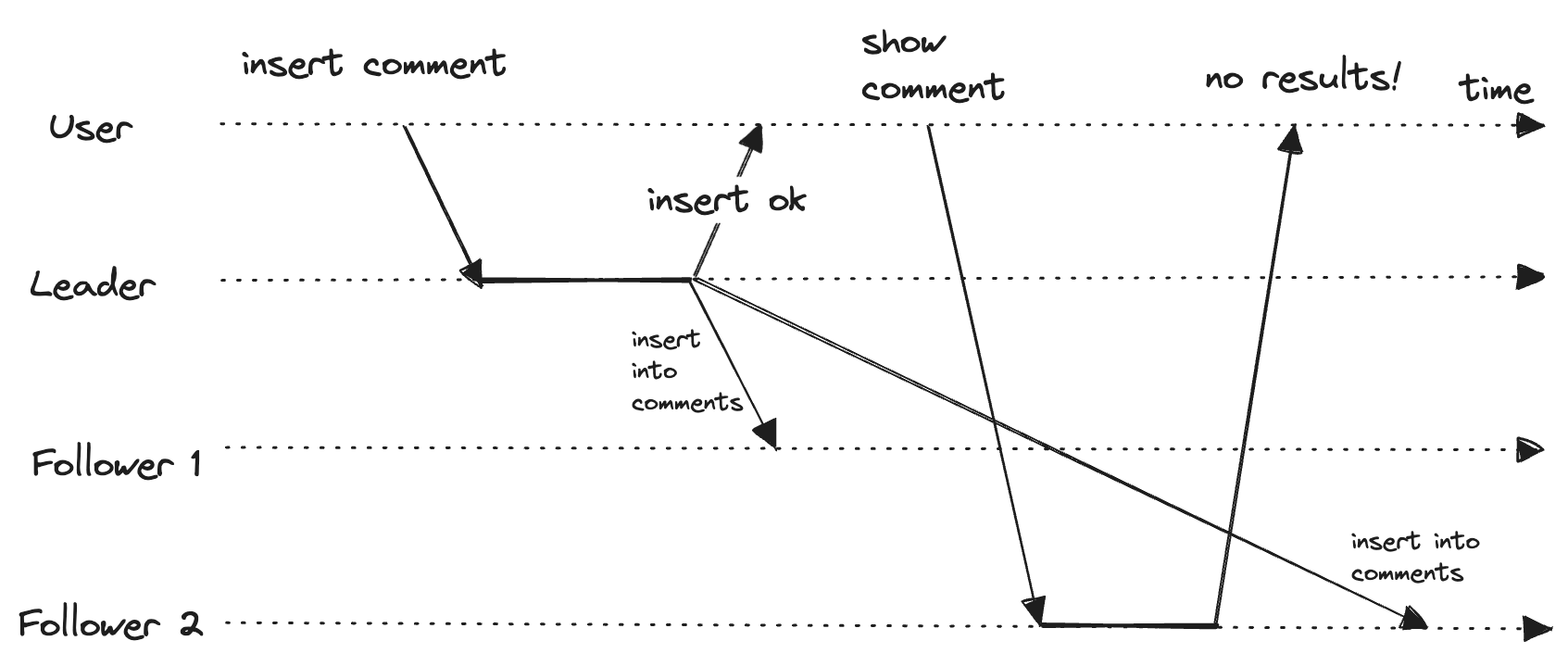
Many applications allow the user to submit some data and then view what they have submitted, for example, comment in a discussion, buy a stock, etc. The submitted data is sent to the leader and read by the follower, but if we have asynchronous replication, it is a problem. The new data may have not reached the replica. It seems like the data is lost.
In this situation, we need read-after-write consistency, also known as read-your-writes consistency. It guarantees that if the user reloads the page, they will always see the updates that they have submitted. It doesn’t hold for other user’s updates, and it will take some time to reflect them.
But how do we implement it? The initial thought process should be to read from the leader the data that the user may have modified. For example, user info can only be edited by the user itself, so a simple rule is that the user profile is read from the leader and any other user’s profile from a follower. But if most things are editable by the user, then the benefit of read scaling will be negated. In this case, track the time of the last update and serve the reads from the leader after a minute of the last update.
Another complication arises if the user is using multiple devices to access the service. Let’s say the user comments under an Instagram photo and checks the comment from another device. In this case, we need cross-device read-after-write consistency. Approaches that require remembering the timestamp of the last update need to be centralized. Another issue is that the request might not be routed to the same data center for multiple devices, so there might be read inconsistencies. If your approach requires reading from the leader, we may first need to route requests from all of a user’s devices to the same data center.
Monotonic Reads
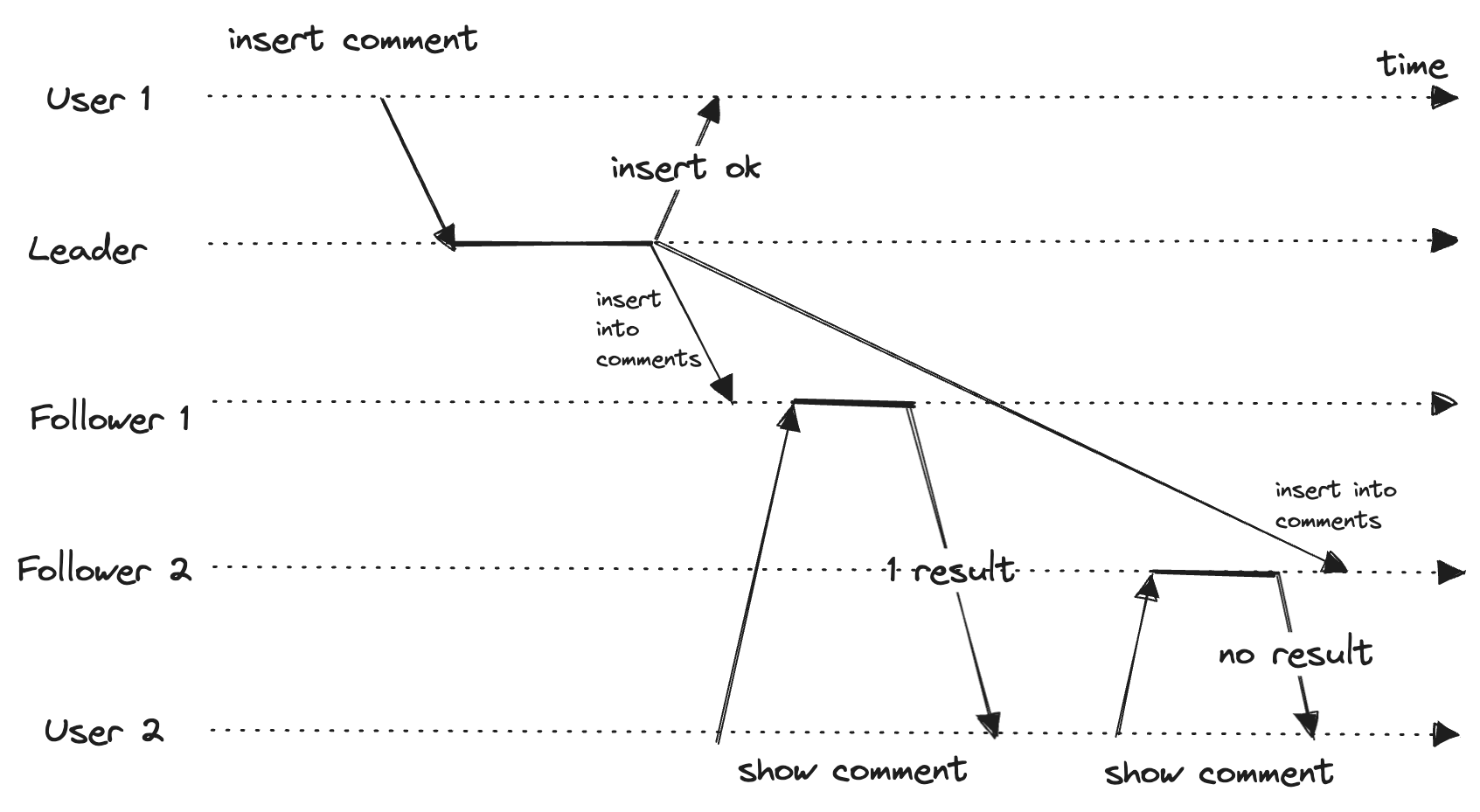
If the user makes multiple reads from different replicas as the user refreshes the web page, each request is served from a random server. The user sees time moving backward because the data hasn’t persisted on all the replicas.
Monotonic reads is a guarantee that this kind of anomaly doesn’t happen. It’s a lesser consistency than strong consistency but a stronger guarantee than eventual consistency. One way of achieving this is by serving all the reads for a user from the same replica chosen by the hash of the userID.
Consistent Prefix Reads
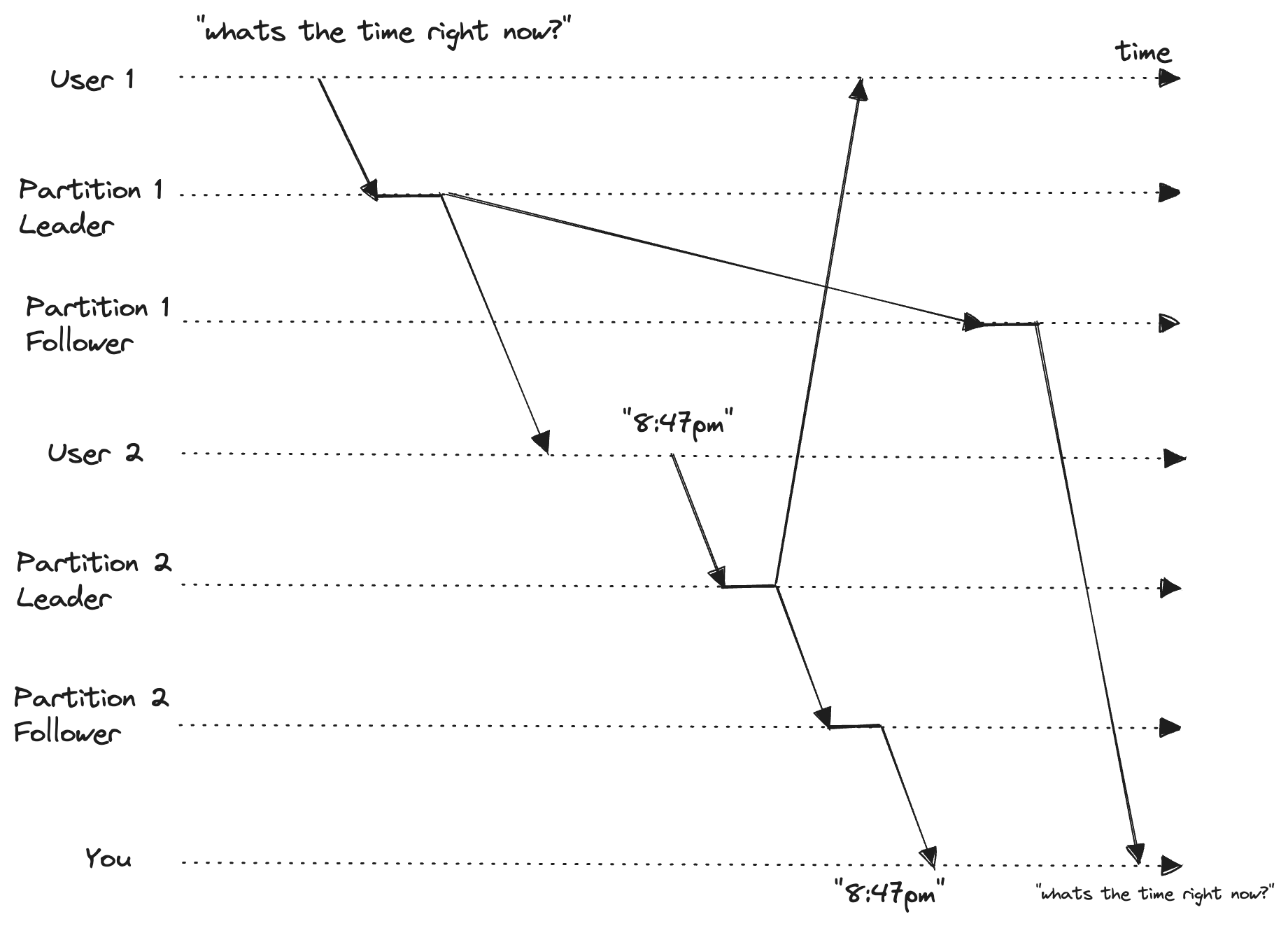
Let’s suppose you are in a WhatsApp group of 3 people, and all 3 of you are exchanging messages. Now you see the sequence of messages not making any sense. Your friend is replying to messages that haven’t arrived, and it feels like he can see the future.
Consistent prefix reads guarantees that if a sequence of writes happens in a particular order, anyone reading those writes will see them appear in the same order. One solution to this problem is to make sure that any writes that are causally related to each other are stored in the same partition.
Multi-Leader Replication
Leader based replication has one major downside, it has only one leader. If we aren’t able to connect to the leader for any reason, we can’t write to the database. The obvious answer to this problem is to have more than one node that accepts writes. This is called multi-leader configuration, also known as master-master or active/active replication
Single-Leader v/s Multi-Leader Configuration in Multi-Data Center Deployment
Performance
In a single-leader configuration, all writes go to the data center with the leader, which adds significant latency to writes, compared to a multi-leader configuration where every write is processed in the local data center and is replicated asynchronously to the other data center. The inter-data center network delay is hidden from the user, which means the perceived performance may be better.
Tolerance of Data Center Outages
In a single-leader configuration, if the data center with the leader fails, failover can promote a follower to the leader in another data center. In a multi-leader configuration, it continues to operate independently of the others, and replication catches up when the failed data center comes back online.
Tolerance of Network Problems
A single-leader configuration is very sensitive to problems in this inter-data center link because writes are made asynchronously over this link. A multi-leader configuration with asynchronous configuration can tolerate network problems better as it doesn’t prevent it from processing writes.
A big downside of multi-leader configuration is that the same data can be modified in 2 different places, causing write conflicts. Auto-incrementing keys, triggers, and integrity constraints can be problematic.
Handling Write-Conflicts
Synchronous v/s Asynchronous Conflict Detection
In a single-leader database, the 2nd writer is either blocked or queued, waiting for the first write to complete or aborted, forcing the user to retry the write. In a multi-leader setup, both the writes are accepted, and the conflict is only detected asynchronously at some later point in time. We could’ve made the conflict detection synchronous in a multi-leader setup i.e. wait for the first write to be replicated to all the replicas before telling the user the write was successful. But this would make us lose on the benefit of multi-leader replication to allow each replica to accept writes independently. Use single-leader replication if you want synchronous conflict detection.
Converging Towards a Consistent State
A single-leader database applies the writes in sequential order, meaning that if there are multiple updates to the same field, the last write determines the final value of the field. In multi-leader configuration, there is no defined ordering of writes, so it’s not clear what the final value of the field will be.
Various ways of achieving convergent conflict resolution
- Give each write a unique ID, pick the write with the highest ID as the winner, and throw all the other writes. If a timestamp is used, the technique is called last write wins (LWW). But this is prone to data loss.
- Give each replica a unique ID, and let the writes that originated at a higher-numbered replica always take precedence over writes that originated at a lower-numbered replica. But this is also prone to data loss.
- Record the conflict in an explicit data structure that preserves all information, and write application code that resolves the conflict.
Custom Conflict Resolution Logic
Most multi-leader replication tools let us write conflict resolution logic using application code that may execute on read or on write.
- on write - As soon as the system detects a conflict in the log of replicated changes, it calls the conflict handler.
- on read - When a conflict is detected, all the conflicting writes are stored. The next time data is read, multiple versions of the data are sent back to the application. The application may prompt the user to manually resolve the conflict.
Conflict resolution usually applies on a row or document level and not to a complete transaction.
Automatic Conflict Resolution
- Conflict-free replicated datatypes (CRDTs) are a family of data structures for sets, maps, ordered lists, counters, etc that can be concurrently edited by multiple users and which automatically sensibly resolve conflicts. It uses 2-way merge function
- Mergeable persistent data structure tracks history explicitly, similarly to the git version control, and uses a 3-way merge function
- Operational transformation is the conflict resolution algorithm behind collaborative editing applications such as Google Docs. It is designed particularly for concurrent editing of an ordered list of items.
Parting Words
The second part of the blog series introduced the different consistency guarantees other than strong consistency and eventual consistency. It also gave an in-depth introduction to multi-leader configuration, where we compared it to single-leader configuration.
If you liked the blog, don’t forget to share it and follow me on Twitter, LinkedIn, Peerlist, and other social platforms, and tag me. You may also write to me at guptaamanthan01@gmail.com to share your thoughts about the blog.
References
- Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann