Data Structures That Power Your Databases
Have you ever thought about why databases are so complex internally and why we can’t use a text file to store the data? This blog post aims to go from the most basic database that writes data to text files to a more complex setting where we use LSM-tree and B-tree. We will understand why we need these data structures and more.
World’s Simplest Key-Value Store
What does the world’s simplest key-value store look like? 2 bash function that writes data to a text file and gets data from the text file.
db_set(){
echo "$1, $2" >> database
}
db_get(){
grep "^$1," database | sed -e "s/^$1,//" | tail -n 1
}
Let me explain both the functions.
- The db_set() function appends to the end of the file without any logic. That means if you update the value of a key, it will not overwrite the value but create a new key value at the end of the file.
- The db_get() function gets the last occurrence of the key.
What’s the problem with this implementation?
- Doesn’t deal with concurrency control, reclaiming disk space, handling errors, and partially written records.
- db_get() function has terrible performance as it takes O(n) to lookup for a record.
To efficiently find the value of a key, we need a different data structure: an index. The general idea behind indexes is to keep some additional metadata on the side, which acts as a signpost and helps you locate the data you want. But this comes with a tradeoff as it slows down writes but offers fast reads.
Hash Indexes
I am not planning to dive deep into the workings of a hash indexes in this particular blog. I plan on covering it in a future blog, but till then, you can refer to this blog to understand more about it.
Let’s again go back to our key-value store. The strategy to improve the lookup speed is to keep an in-memory hash map where every key is mapped to a byte offset in the file. Whenever a new key is appended to the file, the hash map is also updated to reflect the offset.
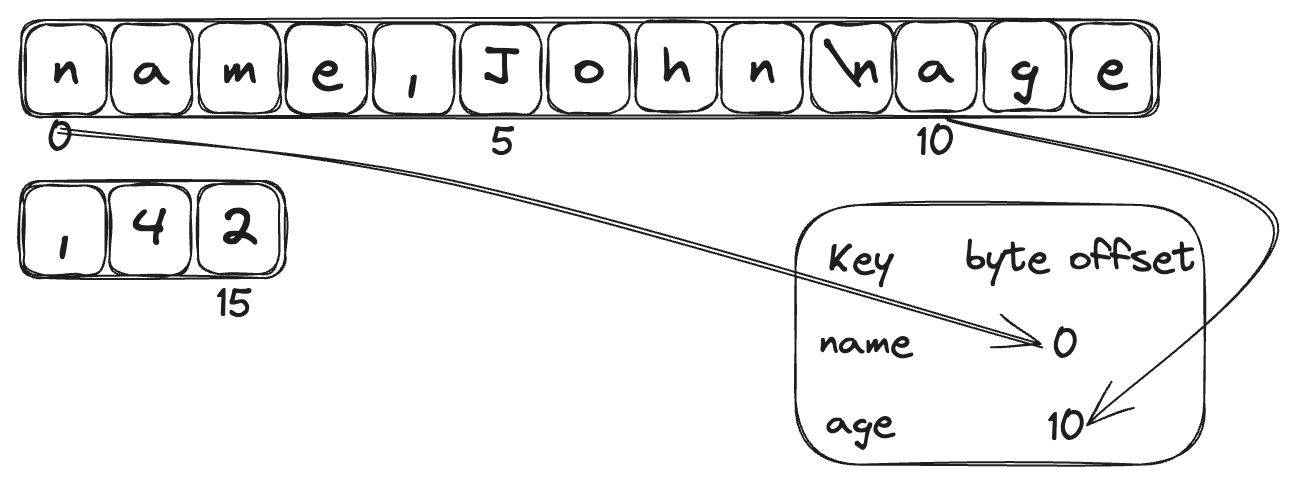
How do we avoid running out of disk space as we are only appending to the file?
We break the files into smaller segments and perform compaction on each segment. Compaction is throwing away the duplicate keys in the file and keeping only the most recent update for each key. We can perform compaction over multiple segments together at the same time. Segments are never modified, so the merged segment is written to a new file. It is done in the background while we serve read and write requests using the old segment files.
But there are some things to take care of with the implementation and limitations of the hash table index:
- Hash table must fit in memory because, on disk, it is hard to get the same performance
- We can’t do range queries efficiently
- If the database is restarted, the in-memory hash maps are lost. We rebuild the index by reading the entire segment file from beginning to end. It will take a lot of time. We can have a snapshot of each segment’s hash map on disk to solve this issue
- Database may crash halfway through appending a record that can be resolved by including checksums
- Writes are appended to the file in a strictly sequential order. A common implementation is to have only 1 write thread and multiple read threads
- When merging segments, the tombstone tells the merging process to discard any previous values for the deleted key
SSTables
A simple change to our segment files can help us get rid of maintaining the hash index with all keys. We store the key-value pairs in a sorted-by-key order. We call this format SSTable
What advantages do we gain over the hash index?
Merging the segment files gets simple and efficient even if the files are larger than the available memory. The merge sort algorithm is used to create new merged segment files, also sorted by key. We now don’t need to maintain an index of all keys in memory. We build a sparse index where we get the keys between which our key lies. It saves disk space and I/O bandwidth.
How is this SSTable constructed and maintained?
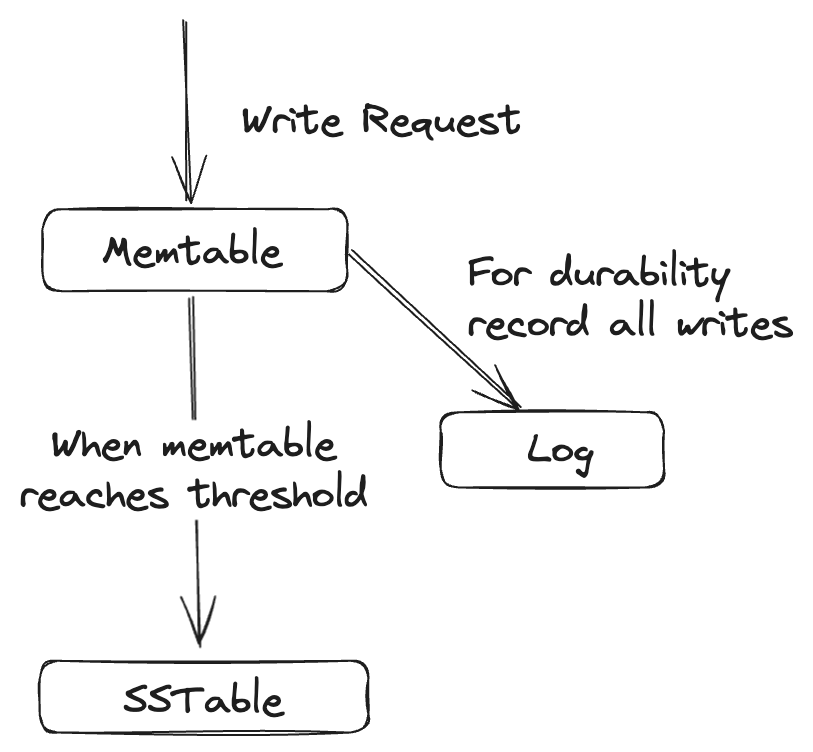
When writes come in we add it to the in-memory tree memtable. When it gets bigger than a threshold, we write all the data from the memtable to the SSTable file. The new SSTable file becomes the most recent segment of the database. While we write to SSTable, writes continue to new memtable instance. When read requests come in we first search for the key in memtable then in the most recent on-disk segment, then in the next older segment and so on. And from time to time we run compaction in the background. We can also keep a seperate log on disk to which every write is immediately appended for durability purposes.
LSM Tree
Log-structure merge-tree or LSM tree is a clever algorithm based on the above principle of merging and compacting sorted files. LSM is append-only as we only append all the modfications to the SSTable.
The LSM tree algorithm can be slow when looking up keys that do not exist in the database. We first check the memtable and then all the segments. Storage engines use Bloom Filters to optimize the algorithm.
A bloom filter is a memory-efficient data structure for approximating the contents of a set. It can tell if a key exists in the database and thus save many unnecessary disk reads for keys that don’t exist.
B Tree
B Tree keeps key-value pairs sorted by keys like SSTable, which allows efficient key lookups and range queries. It breaks down the database into fixed-size blocks or pages, traditionally 4Kb in size, and reads or writes one page at a time. This design corresponds closely to the underlying hardware, as disks are also arranged in fixed-size blocks.
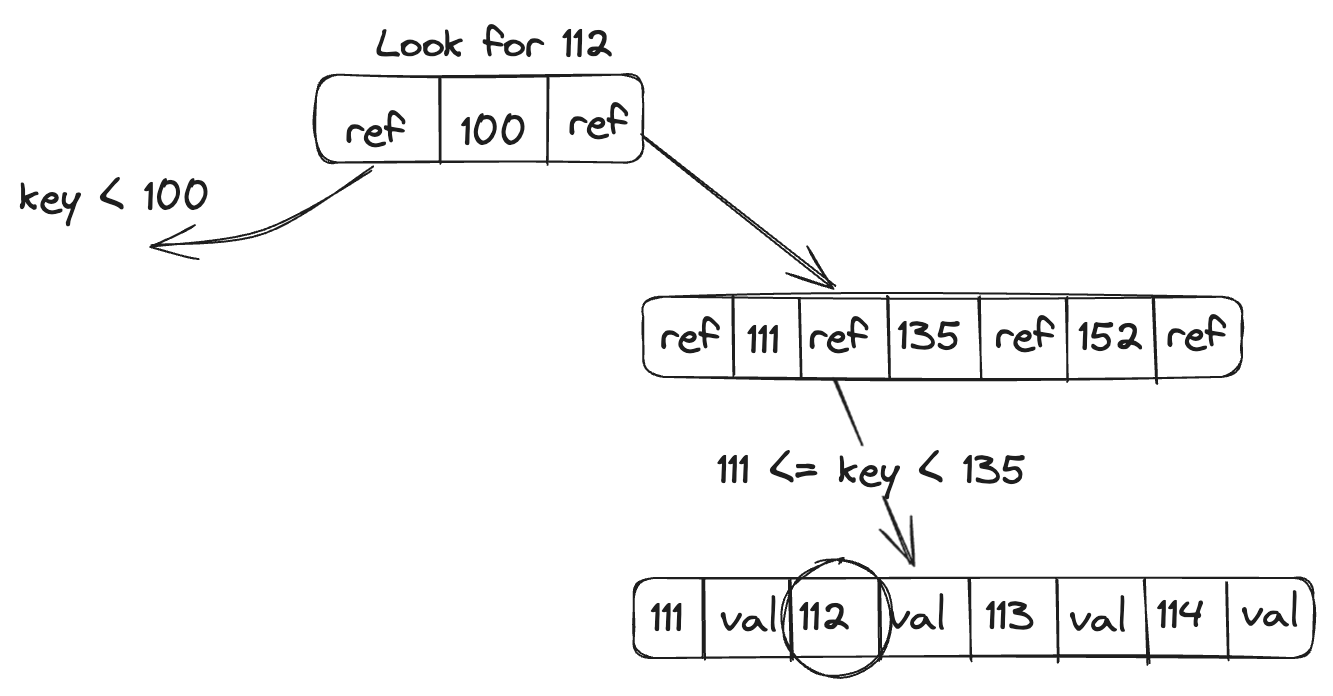
An append-only file where we capture all B tree modifications before applying them to the pages of the tree itself. It is a write-ahead log (WAL or redo log) that helps make the database crash-resilient. We use latches (lightweight locks) to protect our B tree when multiple threads try to access the B tree at the same time.
Which one is better? LSM Tree vs B Tree
- B Tree writes every piece of data at least twice: once to the write-ahead log and once to the tree page itself (and sometimes again when the pages split). The log-structure index rewrites data multiple times due to the repeated compaction and merging of SSTable. It results in one write to the database and multitudinous writes to the disk over the course of the database’s lifetime - known as write amplification. It is a concern on SSDs as a limited number of overwrites can perform before wearing out.
- LSM trees can be compressed better, resulting in smaller files on disk than B trees.
- B tree storage engine leaves some disk space unused due to fragmentation when the page is split or the row cannot fit in an existing table. LSM trees aren’t page oriented and periodically rewrite SSTables to remove fragmentation.
- The compaction process can sometimes interfere with the performance of ongoing reads and writes. At high throughput, the disk’s finite bandwidth is shared between the initial write and the compaction threads running in the background. The bigger the database gets, the more disk bandwidth is required for compaction.
- In B trees, each key only exists in exactly one place in the index, whereas a log-structured storage engine may have multiple copies of the same key in different segments. It makes B trees attractive in databases that want to offer strong transactional semantics.
- LSM trees are typically able to sustain a higher write throughput than B trees. But B trees are thought to offer faster read throughput.
Parting Words
There are definitely more data structures that power databases like skiplist, inverted index, R tree, suffix tree, etc. But this blog introduces to the more famous ones and to help understand the underlying working of them.
If you liked the blog don’t forget to share it on Twitter, LinkedIn, Peerlist, and other social platforms and tag me. You may also write to me on guptaamanthan01@gmail.com to share your thoughts about the blog.
References
- Designing Data-Intensive Applications: The Big Ideas Behind Reliable, Scalable, and Maintainable Systems by Martin Kleppmann